Patient Matching Software: What It Is And Use Cases In EHRs

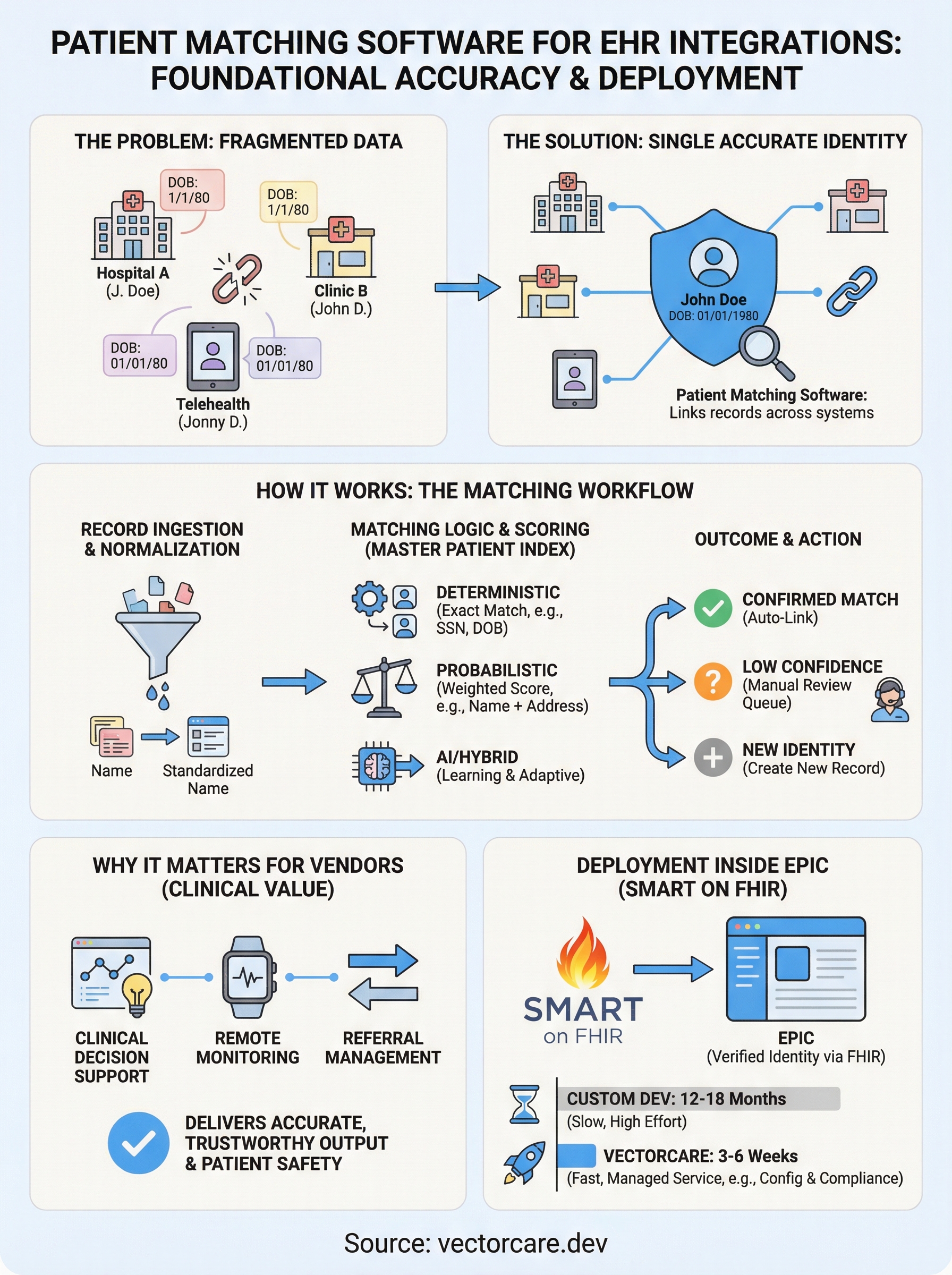
A single patient can have records scattered across five or more healthcare systems, each with slightly different name spellings, outdated addresses, or mismatched identifiers. When those records don't connect, clinicians make decisions with incomplete information. Patient matching software exists to solve exactly this problem: it links fragmented records to a single, accurate patient identity across every system that touches care delivery.
For healthcare vendors building tools that sit inside EHR workflows, accurate patient matching isn't optional, it's foundational. Whether you're developing clinical decision support, remote monitoring, or referral management solutions, your product depends on pulling the right data for the right patient. That's where SMART on FHIR integrations with systems like EPIC become critical, and it's why platforms like VectorCare help vendors deploy EHR-integrated applications without building the technical infrastructure from scratch.
This article breaks down what patient matching software actually does, how it works, and where it fits into EHR-driven clinical workflows. You'll also learn about core use cases, from enterprise master patient indexes to clinical trial recruitment, and what to consider when evaluating these solutions for your own product.
Why patient matching matters in healthcare
Healthcare data is fragmented by design. Patients receive care at hospitals, specialty clinics, urgent care centers, telehealth providers, and pharmacies, and each of those systems stores records independently. Without reliable patient matching software, a single person can exist as multiple separate identities across your ecosystem, creating dangerous gaps in care history, medication lists, and diagnostic results. For any vendor building tools that touch clinical workflows, this fragmentation is a direct obstacle to delivering accurate, trustworthy output.
Duplicate patient records affect up to 10% of records in a typical hospital system, and the downstream impact reaches everything from billing accuracy to patient safety.
The cost of duplicate and mismatched records
When records don't merge correctly, duplicate entries accumulate fast. A patient who receives care at three facilities might have five or six separate records, each missing pieces of the clinical picture. For healthcare vendors, your product only delivers real value when it works from a complete and accurate data set. Mismatches create direct financial and operational problems, including:
- Redundant diagnostic tests ordered because prior results aren't visible in the active record
- Insurance claim denials caused by conflicting patient identifiers across systems
- Increased administrative time spent manually reconciling records before care decisions can be made
How matching errors affect clinical decisions
Clinicians depend on the longitudinal record, meaning the full history of a patient's diagnoses, labs, and medications, to make informed decisions. When patient matching fails, that record becomes unreliable. A physician might prescribe a medication without knowing about a prior adverse reaction that's documented in a different system under a slightly different name spelling.
For vendors building clinical decision support or remote monitoring tools, incomplete patient data undercuts every recommendation your product makes, regardless of how sophisticated your underlying logic is. Patient safety risks linked to record mismatches are well-documented and flagged by bodies like the Office of the National Coordinator for Health Information Technology. Building matching accuracy into your integration from the start is the only reliable way to protect both patients and your product's credibility.
The main types of patient matching software
Not all patient matching software uses the same logic. The approach your integration relies on determines how well it handles real-world data inconsistencies like name variations, transposed birth dates, or records created across multiple facilities.
Deterministic and probabilistic matching
Deterministic matching compares fixed fields like name, date of birth, and Social Security number, confirming a match only when all defined criteria align exactly. It performs well in controlled settings but fails when data entry varies across systems or when patients have registered under different information at different facilities.

Probabilistic matching assigns weighted scores to individual fields and calculates an overall likelihood of a match even when records differ. You can tune the thresholds to balance precision against recall depending on how your product handles imperfect or incomplete data at scale.
Probabilistic methods outperform deterministic rules whenever patients have changed their name, moved, or received care at multiple unconnected facilities.
AI-powered and hybrid matching
Machine learning models build on probabilistic logic by learning from historical match decisions and adjusting weights automatically over time. These systems handle complex, multi-source data environments better than static rule sets, and they improve as more data flows through them. Many platforms now combine all three approaches in a hybrid model, which works well for:
- Reconciling records after health system mergers or acquisitions
- Matching patients to clinical trial eligibility criteria
- Linking data from remote monitoring devices or external vendor platforms
How patient matching works in real workflows
Understanding the theory behind patient matching software is useful, but seeing how it operates step by step inside a real clinical workflow makes the value concrete. Most matching processes follow a consistent sequence from the moment a record enters a system to the point where a clinician or downstream application receives verified patient data.
When a patient record enters the system
Every matching process starts with record ingestion, where incoming patient data gets normalized. Fields like names, dates of birth, and addresses are standardized to remove formatting inconsistencies before any comparison happens. The system then queries its master patient index to find candidate records that share overlapping attributes, scores them against the incoming record, and either confirms a match, flags a potential duplicate, or creates a new identity.

This normalization step is where most matching failures originate, systems that skip it produce unreliable scores regardless of how sophisticated their matching logic is.
What happens when confidence is low
When the match confidence score falls below a defined threshold, the record moves to a manual review queue rather than auto-linking. A trained staff member reviews the flagged candidates side by side and makes the final call. Your integration needs to account for this queue in its design, because unresolved records stay unavailable to downstream tools until a reviewer acts on them, which directly affects how your product performs in live clinical settings.
What to look for in patient matching tools
Choosing the right patient matching software comes down to more than raw accuracy numbers. Your vendor selection shapes how reliable your product's data layer is, and that affects every clinical output your application generates. Before committing to a platform, test it against your actual data environment rather than a controlled demo.
Matching accuracy and configurability
Match rate benchmarks matter, but so does how the system handles edge cases. Look for platforms that let you configure confidence thresholds separately for auto-link, manual review, and auto-reject decisions. A rigid system with no tuning options forces your team into constant manual intervention as data volume grows.
Platforms that expose configurable match rules give you measurable control over false positive rates, which directly protects patient safety and your product's credibility.
Key accuracy features to evaluate:
- Adjustable threshold settings per match category
- Support for both deterministic and probabilistic logic
- Transparent scoring explanations for auditing purposes
Integration compatibility and compliance
Your matching tool needs to connect cleanly to FHIR-based data pipelines, especially if your product runs inside EHR environments. Confirm it supports HIPAA-compliant data handling end to end, including audit logging, role-based access controls, and Business Associate Agreements.
Gaps in any of these areas will block your product from clearing health system security reviews before you reach clinical deployment.
How vendors deploy matching inside Epic workflows
When you build a product inside Epic, patient matching software doesn't operate in isolation. Epic maintains its own Enterprise Master Patient Index, which means your application inherits Epic's existing matching logic rather than building a separate patient identity layer from scratch. That architecture shapes how you connect to patient data at every layer of your integration.
Using SMART on FHIR to access verified identities
Epic exposes patient identity through SMART on FHIR endpoints that return records already processed by Epic's matching engine. Your application receives a verified FHIR Patient resource with a stable Epic-assigned identifier, so identity resolution happens before your product logic ever runs.
A correctly scoped SMART on FHIR integration delegates the hardest parts of patient identity resolution to Epic's own infrastructure.
This only works if your OAuth scopes and FHIR resource configuration are correct from the start. Most teams underestimate that setup complexity, which is where integration projects stall before reaching clinical deployment.
What this means for your deployment timeline
Building a compliant FHIR integration from scratch takes most teams 12 to 18 months. Platforms like VectorCare compress that to 3 to 6 weeks by handling FHIR configuration, Epic Showroom submission, and compliance requirements as a fully managed service.
Your engineering team skips the identity infrastructure entirely and focuses on your core product. That produces a faster path to market and a significantly lower cost structure than custom development alone.
Next steps
Patient matching software sits at the foundation of every reliable EHR integration. Without accurate identity resolution, your application delivers incomplete data to clinicians, and incomplete data undermines the entire value your product is built to provide. The core decision you face is straightforward: build the matching and integration infrastructure yourself, or leverage a platform that handles it for you.
Most healthcare vendors who try the custom route discover that FHIR configuration, Epic compliance reviews, and identity pipeline maintenance consume far more engineering time than they planned for. That time delays your go-to-market and pulls your team away from the product features that actually differentiate your offering.
If you want to deploy inside Epic workflows faster without building the integration layer from scratch, VectorCare manages that entire process, from SMART on FHIR configuration to Epic Showroom listing. See how VectorCare accelerates your Epic integration and get your application in front of health systems in weeks, not months.
The Future of Patient Logistics
Exploring the future of all things related to patient logistics, technology and how AI is going to re-shape the way we deliver care.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.