Referential Patient Matching: How It Works And Why Matters

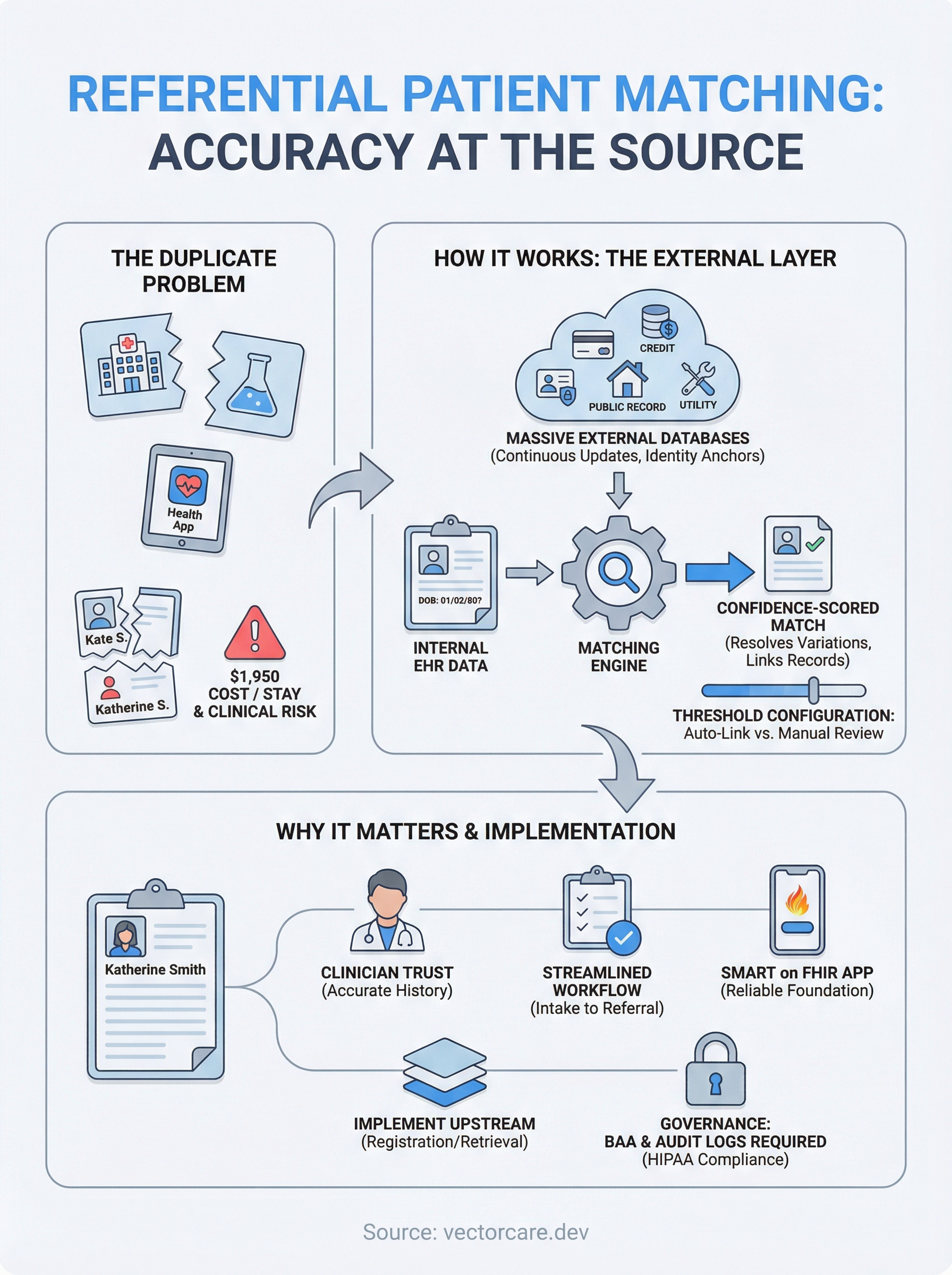
Duplicate patient records cost U.S. hospitals an estimated $1,950 per inpatient stay and contribute to medical errors that put lives at risk. At the center of solving this problem sits referential patient matching, a technology that cross-references patient demographics against massive external databases to verify identities and link records that belong to the same person. Unlike older deterministic or probabilistic methods that rely solely on internal data, referential matching pulls from credit bureaus, public records, and other third-party sources to fill in gaps and resolve ambiguities.
For healthcare vendors building integrations with EHR systems like EPIC, patient matching accuracy isn't optional, it's foundational. Every clinical workflow that surfaces patient data, from intake forms to referral management, depends on pulling the right record for the right person. That's exactly the kind of challenge we deal with at VectorCare. Our no-code platform helps healthcare vendors deploy SMART on FHIR applications into EPIC, and clean, accurate patient identification is a prerequisite for every integration we support.
This article breaks down how referential patient matching works, what makes it different from traditional approaches, and why it matters for healthcare organizations trying to reduce duplicates and improve data quality. Whether you're a digital health startup building your first EHR integration or an established vendor looking to strengthen your data accuracy story, understanding this technology gives you a clearer picture of the infrastructure that supports modern clinical workflows.
Why it matters in healthcare
Healthcare organizations generate patient data across dozens of systems: hospitals, labs, pharmacies, specialist offices, and health apps. Every system creates its own record, and without a reliable way to link those records to the same person, your data infrastructure starts to fracture. Referential patient matching addresses this at the source by verifying patient identities against external reference databases before a mismatch has the chance to propagate through your systems.
The scale of the duplicate record problem
Duplicate patient records are more widespread than most people expect. Research from health information exchanges has flagged that duplicate rates in hospital systems typically range from 8% to 12%, with some networks reporting figures as high as 20%. When you consider that a large health system manages millions of patient records, even an 8% duplicate rate translates to hundreds of thousands of records that either point to the wrong person or split one person's medical history into multiple disconnected files.

A single duplicate record can result in a clinician making a treatment decision based on incomplete medical history, which directly increases patient safety risk.
The financial side compounds the problem. Each duplicate record costs hospital systems an average of $1,950 per inpatient stay to resolve, covering manual review time, rebilling, and the downstream corrections needed to clean up the data trail. For vendors building healthcare applications, this means your product may be operating on top of data that's already compromised before your app runs a single query.
Clinical workflow disruptions
Incorrect patient matching creates friction at every touchpoint in a clinical workflow. When a provider pulls up a patient record to review prior authorizations, lab results, or medication history, they need confidence that they're looking at one complete, accurate file. If your application surfaces a fragmented or duplicated record, you slow down the clinical team, increase the risk of redundant testing, and erode the trust that health systems place in your product before they'll expand its use.
For healthcare vendors integrated with EPIC or other EHR systems, these problems scale fast. A single FHIR query that returns the wrong patient context can push an entire workflow off track, from intake to referral routing to order management. The more data-intensive your application, the higher the stakes for getting patient identification right from the start.
Why traditional matching methods create gaps
Deterministic matching works well when data is clean and complete. It compares fields like name, date of birth, and social security number, then flags records as matches only when those fields align exactly. The problem is that real-world patient data is messy: names get misspelled at registration, addresses change frequently, and date-of-birth entry errors are common across intake systems.
Probabilistic matching improves on this by scoring the likelihood of a match across weighted fields, but it still operates entirely within the boundaries of your internal data. Neither approach can account for what your system doesn't already know, which is where referential matching introduces a meaningful advantage. By pulling from verified external identity sources, your matching logic gains a richer, more current foundation. For healthcare vendors building products that need to function reliably across multiple health systems with different data quality standards, that external reference layer changes what's possible.
How referential patient matching works
Referential patient matching runs a comparison between patient demographic data in your system and records held in large, continuously updated external identity databases. Instead of only checking whether two internal records share the same name and birthdate, the process routes your patient data through a third-party reference layer, then returns a confidence-scored identity match that accounts for variations, gaps, and changes in that data.
The step-by-step matching process
When a patient registration event triggers the matching workflow, your system sends a set of demographic identifiers such as name, date of birth, address, and partial social security number to the referential matching engine. That engine queries its external reference database, which typically contains hundreds of millions of identity records sourced from credit bureaus, utility providers, and government records. The engine then scores the query results and returns match candidates ranked by confidence level.

The quality of your match depends directly on how current and broad your reference database is, which is why the data source behind the engine matters as much as the algorithm itself.
Your system receives that ranked output and either auto-links records at high confidence thresholds or flags lower-confidence results for manual review. This keeps the workflow moving without forcing a clinician to pause every time a name carries an alternate spelling or an address changed in the past year.
How the reference layer resolves edge cases
Real-world patient data regularly breaks deterministic matching rules. A patient registered as "Katherine" in one system may appear as "Kate" in another, and a date-of-birth typo at intake can produce a near-miss that traditional probabilistic scoring never fully recovers. The external reference layer fills those gaps by cross-checking additional identity signals that internal data simply does not carry.
Handling name changes, address histories, and multi-system discrepancies that accumulate naturally over a patient's lifetime is where referential matching delivers its clearest advantage over internal-only approaches. By anchoring your match logic to verified external identity data, you reduce the manual reconciliation burden on your team and give every downstream clinical workflow a cleaner, more reliable patient record to operate from.
Data sources, privacy, and governance
The reference layer behind referential patient matching is only as reliable as the data that feeds it. External identity databases typically aggregate records from credit bureaus, utility companies, postal services, and public records, pulling from sources that update continuously as people move, change names, or open new accounts. The breadth and freshness of this data determines how well your matching engine handles real-world patient demographics, so understanding what sits inside the reference database matters before you commit to a vendor or implementation approach.
Where external identity data comes from
Credit bureau data is one of the most commonly used reference sources because it captures name variations, address histories, and identity linkages across millions of individuals at a level of frequency that healthcare registration systems rarely match. Postal service records fill in address accuracy gaps, while government datasets contribute verified identity anchors. When combined, these sources give the matching engine multiple corroborating signals for each patient identity, which reduces the chance that a single data gap in your EHR breaks the match.
The more diverse and current your reference database, the more resilient your matching logic becomes against the inconsistencies that naturally accumulate across health system data.
How HIPAA and governance requirements apply
Sharing patient demographics with an external matching service introduces data handling obligations that you need to address directly. Under HIPAA, any vendor that receives protected health information in order to perform a service on your behalf qualifies as a business associate, which means you need a signed Business Associate Agreement (BAA) in place before any data flows to the referential matching engine. For healthcare vendors building SMART on FHIR applications, this is not a step you can defer, since health systems will ask for it during contract review.
Your governance framework also needs to cover data minimization and retention policies. Most referential matching workflows transmit only the demographic fields required to run the match, not full clinical records, but you still need documentation that confirms this. Building a clear data flow map and retaining audit logs of every matching transaction keeps your compliance posture solid and gives your health system partners the transparency they need to approve your integration.
Accuracy, risks, and how to evaluate it
Referential patient matching can significantly improve your match rates, but no matching system is perfect. False positives, where two different patients get linked as the same person, carry serious clinical consequences, and false negatives, where the same patient's records fail to connect, leave gaps in medical history that clinicians rely on. Understanding both failure modes gives you a realistic picture of what accuracy means in this context and what you need to evaluate before committing to any solution.
Understanding match rate and false positive risk
Match rate tells you the percentage of patient records your system successfully links to a verified identity. A high match rate looks good on paper, but it only tells part of the story. If your engine is tuned too aggressively toward matching, you increase the risk of false positives, records incorrectly linked to the wrong patient identity. In a clinical setting, that means a provider could access the wrong patient's medication history or lab results.
Tuning your matching engine is a tradeoff between sensitivity and specificity, and getting it wrong in either direction creates real patient safety exposure.
False negatives carry their own risks. When your system fails to link two records that belong to the same person, clinicians work with an incomplete view of that patient's history. This is especially common with patients who have changed names, moved, or registered at multiple facilities using slightly different demographic information. Referential patient matching reduces this risk by anchoring matches to external identity signals, but your configuration thresholds still determine how aggressively the engine pursues those links.
What to look for when evaluating a vendor
When you assess a referential matching vendor, database size and update frequency are your first two filters. A reference database that covers hundreds of millions of identities and refreshes continuously gives your matching logic far more to work with than a static or infrequently updated source. Ask vendors directly how often their reference data refreshes and what sources contribute to it.
Beyond the data layer, review the vendor's documented false positive and false negative rates across real healthcare deployments, not just benchmark datasets. Confirm that the system gives you configurable confidence thresholds so you can set the sensitivity level appropriate for your specific clinical context and manual review capacity.
How to implement it with EHRs and apps
Implementing referential patient matching inside an EHR integration requires more than selecting a matching vendor. You need to connect the matching layer to the right point in your data pipeline, configure the confidence thresholds that fit your clinical context, and make sure your application handles both auto-linked and flagged records without disrupting the clinical workflow. Getting those three things right before go-live saves you significant remediation work later.
Connecting the matching layer to your EHR
Your matching engine needs to sit upstream of any patient data write or read operation in your integration. The most reliable placement is at registration or record retrieval, before your application surfaces any clinical data to an end user. When a patient record enters the workflow, your system sends the relevant demographic fields to the referential matching engine, receives a confidence-scored response, and routes that result to either an auto-link action or a manual review queue based on your threshold configuration.
Placing the matching layer after a record has already been written into your system means you are cleaning up errors instead of preventing them, which costs significantly more time and effort.
For EPIC integrations built on SMART on FHIR, you can invoke the matching logic as part of the FHIR patient search or patient read flow. FHIR's Patient resource carries the demographic fields your matching engine needs, and you can structure your FHIR query to trigger the external match before returning results to your application's UI.
Embedding matching logic in SMART on FHIR apps
SMART on FHIR apps launch within the EHR context, which means the patient context your app receives at launch is only as accurate as the underlying record. If the EHR already carries a duplicate or fragmented record, your app inherits that problem. Building a matching validation step into your app launch sequence gives you a reliable check before your application logic runs.
You can structure this as a lightweight background call that validates the patient identifier against your referential matching service. When the match returns with high confidence, your app proceeds normally. When confidence falls below your threshold, your app surfaces a review prompt so the clinical user can confirm identity before continuing. This keeps the workflow smooth and keeps your patient data trustworthy across every integration instance.
Next steps
Referential patient matching is not a feature you bolt on after your integration goes live. It belongs at the foundation of how your application handles patient data, from the first registration event to every subsequent workflow that surfaces clinical information. Getting this right before you launch protects your health system partners, reduces remediation costs, and strengthens the trust that drives contract renewals and expansion.
If you are building a SMART on FHIR application for EPIC, the implementation decisions you make around patient identity, data governance, and EHR workflow integration will shape how your product performs across every health system that deploys it. The technical complexity is real, but it is manageable when you have the right infrastructure underneath your application.
VectorCare handles those layers for you. From FHIR configuration to compliance to EPIC Showroom listing, our platform gets your app live in weeks, not months. See how VectorCare deploys SMART on FHIR apps and start building today.
The Future of Patient Logistics
Exploring the future of all things related to patient logistics, technology and how AI is going to re-shape the way we deliver care.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.