MPI vs EMPI: Key Differences in Patient Matching Across EHRs

When a healthcare vendor pulls patient data through a SMART on FHIR integration, something has to guarantee that the right record gets matched to the right person. That "something" is either a Master Patient Index or an Enterprise Master Patient Index, and the distinction between MPI vs EMPI matters more than most vendors realize. Get it wrong, and you're dealing with duplicate records, mismatched data, and compliance headaches that can stall a health system contract before it starts.
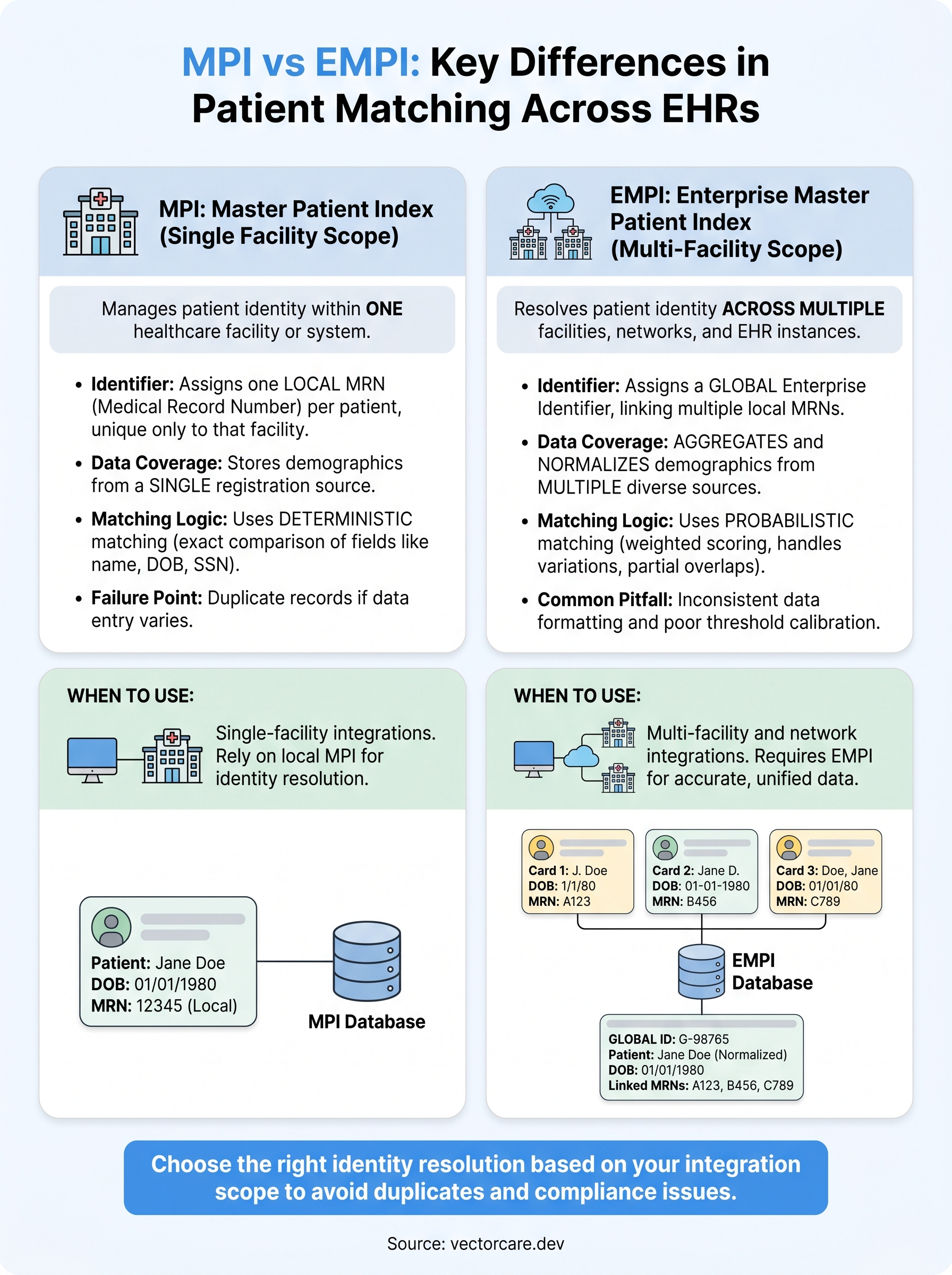
An MPI handles patient identity within a single facility or system. An EMPI does the same job across multiple facilities, networks, and EHR instances. For healthcare vendors building integrations with platforms like EPIC, understanding how each one works, and where your application fits into that identity resolution chain, is critical to delivering accurate, reliable data inside clinical workflows. This is exactly the kind of complexity that VectorCare's no-code SMART on FHIR platform helps vendors navigate, so their apps pull the correct patient context every time they launch inside an EHR.
This article breaks down the technical differences between MPI and EMPI, explains how each approach handles patient matching, and clarifies which one applies when your integration touches single versus multiple healthcare organizations. By the end, you'll have a clear picture of how patient identity management works across EHR systems and why it should shape how you design your integration strategy.
What an MPI and an EMPI do
A Master Patient Index is a database that stores and manages unique patient identifiers within a single healthcare facility, such as one hospital or clinic. When a patient registers at that facility, the MPI assigns them a local ID and links it to their demographics, including name, date of birth, and address. Every clinical system inside that facility, from billing to lab results, references that single ID to pull up the right record. The MPI acts as the internal source of truth for patient identity within its walls.
How a single-facility MPI works
An MPI typically stores one primary record per patient and uses deterministic matching, meaning it compares exact field values like name spelling or social security number to confirm identity. When a new record comes in, the system checks it against existing entries and either merges it with a match or creates a new one. Duplicate records are the most common failure point: a patient who spells their name differently at two visits can end up with two separate records inside the same system.
How an EMPI extends that logic
Unlike an MPI, an Enterprise Master Patient Index resolves patient identity across multiple facilities, networks, or EHR instances that may each use different local IDs, coding standards, or demographic formats. This is where the mpi vs empi distinction becomes operationally significant for vendors building multi-site integrations.
When your integration spans more than one health system, you're no longer working with an MPI. You need EMPI-level identity resolution to avoid pulling the wrong patient's data into your application.
Your EMPI then uses probabilistic matching algorithms alongside deterministic rules to handle data variations across systems. It assigns a global patient identifier that links all local IDs together, giving your application a single, reliable reference point regardless of which facility's records it is reading.
Key differences: scope, data, and identifiers
The most fundamental way to separate MPI vs EMPI is by scope. An MPI operates within a single organizational boundary, managing identifiers that only make sense inside one facility's systems. An EMPI operates across that boundary, linking identifiers from multiple disconnected systems into one coherent patient record. That scope difference drives every other distinction between the two.

Identifier structure and data coverage
An MPI assigns a local medical record number (MRN) that means nothing outside the facility that created it. When your integration queries patient data from a single EPIC instance, that local MRN is sufficient. An EMPI adds a global enterprise identifier that maps across all local MRNs from participating facilities, so your application can follow a patient across sites without losing record continuity.
If your application touches patient data from more than one health system, you need an EMPI-level identifier in your data model, not just a local MRN.
Data coverage also differs significantly between the two. An MPI holds demographics from one facility's registration system only. An EMPI aggregates and normalizes demographics from multiple source systems, resolving discrepancies in name formatting, date formats, and address standards before surfacing a unified record to your application.
How patient matching works in each approach
The matching logic behind an MPI and an EMPI reflects their different scopes. Each approach uses a distinct method to decide whether an incoming record belongs to an existing patient or represents someone new.

MPI matching: deterministic rules
An MPI relies on deterministic matching, which compares exact field values like date of birth, social security number, or name string. If the values align precisely, the system confirms a match. This approach works well when data entry is consistent within a single facility, but it breaks down the moment a patient spells their name differently across two visits.
EMPI matching: probabilistic scoring
An EMPI uses probabilistic algorithms that assign weighted scores to demographic fields across multiple source systems. Instead of requiring exact matches, it calculates the likelihood that two records belong to the same person based on partial overlaps in name, address, and birth date.
When your application pulls patient data across more than one health system, probabilistic matching is what prevents a duplicate or mismatched record from flowing into your clinical workflow.
Understanding the mpi vs empi matching distinction helps you anticipate where identity errors will surface in your integration and design your application to handle them before they reach a clinician.
When to use MPI vs EMPI in real workflows
The right choice in the MPI vs EMPI decision depends on the scope of your integration. If your application connects to a single EPIC instance at one health system, the local MPI that facility already maintains is sufficient for patient identity resolution. Your application receives a local MRN from the FHIR launch context, and that identifier reliably maps to the correct patient record within that system.
Single-facility integrations
When your vendor application serves one health system, you work within that system's existing MPI. You pull the patient's FHIR resource using the local MRN provided at launch, and identity resolution is already handled by the facility's registration system before the data reaches your app. No additional identity layer is required on your side.
Multi-facility and network integrations
Multi-site deployments require EMPI-level identity management when your application connects to more than one health system or facility. A patient treated at two different hospitals carries two separate local MRNs, and without an EMPI linking them, your application sees two different people instead of one.
If you're building for a multi-site rollout, confirm which EMPI solution the health system uses before you finalize your FHIR data model.
Common EMPI pitfalls and how to avoid them
Even when you understand the mpi vs empi distinction, EMPI implementations fail in predictable ways. The most costly mistakes happen before a single patient record is matched, because vendors consistently underestimate how inconsistent source data is across facilities.
Skipping data normalization before matching
Inconsistent formatting across source systems is the most common EMPI failure point. If one facility records birth dates as MM/DD/YYYY and another uses YYYY-MM-DD, your matching algorithm will miss records that should link. Before your integration goes live, normalize all demographic fields, including name casing, address abbreviations, and date formats, to a single standard across every data source your application touches.
Setting match thresholds without testing
Probabilistic matching scores require careful threshold calibration against real data, not default settings. Set the confidence threshold too low, and your EMPI incorrectly merges records from different patients. Set it too high, and it fails to connect records that clearly belong to the same person across two facilities.
Test your match thresholds against real anonymized data from the health systems you're integrating with before you deploy to production.
Regular audits of matched and unmatched record pairs let you catch threshold drift early, before it surfaces as incorrect patient data inside a live clinical workflow.
Final takeaways
The mpi vs empi distinction comes down to one question: how many health systems does your integration touch? If the answer is one, you work within an existing MPI and local identifiers handle everything. If the answer is more than one, you need EMPI-level identity resolution, global identifiers, probabilistic matching, and careful threshold calibration before you deploy.
Building this correctly from the start saves you from duplicate records, mismatched patient data, and failed contract reviews that stall multi-site rollouts. Every design decision in your FHIR integration, from how you model identifiers to how you normalize demographics, connects directly to whether your scope demands an MPI or an EMPI.
Navigating this while also building a compliant SMART on FHIR application is a significant lift. If you want to skip that complexity and get into production faster, explore VectorCare's no-code SMART on FHIR platform and see how quickly your integration can go live.
The Future of Patient Logistics
Exploring the future of all things related to patient logistics, technology and how AI is going to re-shape the way we deliver care.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.